We are all Monets
Team Members
- Sadie Zhao
- Adeena Liang
- Irmak Bukey
- Olina Wong
Abstract
AI-generated artwork has captured the public’s imaginations in recent years. While there are many ways to train AIs to do art, making AIs to imitate styles of great human artists would definitely be an intuitive and effective approach. However, training the machine to learn the style of existing artists is an image-to-image translation problem in absence of paired image input, which was poorly studied and nearly unsolvable until the development of the CycleGAN architecture. This paper provides a detailed explanation, with code implementation, of how CycleGAN enables machines to transfer any photos to Monet style. In addition to the CycleGAN framework, we employed techniques from Deep Convolutional GAN (DCGAN) and traditional image processing and showed how they effectively help to achieve our goal.
Introduction
Writers have their unique prose, musicians have their unique vibe, and no differently, artists have their own unique style that are recognisable in their works throughout their lives. With the development of generative adversarial networks, we can utilise neural networks to imitate any particular style of a specific artist.
With this project, we wish to be able to replicate the style of Monet given any image. People have well-studied the typical image-to-image translation problem, where the goal is to learn the mapping between an input image and an output image using a training set of aligned image pairs. However, for many tasks, paired training data will not be available. In this project, for example, we are given Monet’s paintings as our training data set, while paired training data are unavailable. Thus, we wish to achieve our goal through a recently developed architecture named Cycle-Consistent Adversarial Networks (CycleGANs), which is developed on the base of traditional GANs and aimed at solving unpaired image to image translation problem.
Project Goals
- Explore methods for cleaning the training and test data sets
- Learn and understand generative adversarial networks (GANs) and Cycle-Consistent Adversarial Networks (CycleGANs)
- Train a neural network that is able to transfer any image to Monet style
- Improve the performance of the neural network
Literature Review
Generative Adversarial Networks proposes a new framework for estimating generative models via an adversarial process. The authors introduce a generative and a discriminative model to capture the data distribution and estimate the probability that a sample came from the training data respectively. The framework introduced corresponds to a “minimax two-player game”.
In Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks, an approach for learning to translate an image in the absence of paired examples is introduced. The mapping from a source domain to target domain is strengthened by an inverse mapping from target to source and the introduction of a cycle consistency loss. The approach is applied to various image-to-image translation tasks and shows promising results.
To gain insight on a more general application of conditional adversarial networks, we considered Image-to-Image Translation with Conditional Adversarial Networks which explored conditional adversarial networks as a “general-purpose solution to image-to-image translation problems” due to its ability to learn a loss function to train the given mapping. The authors emphasize the redundancy of “hand-engineered loss functions” as a result of using this approach and demonstrate its effectiveness when applied to a variety of tasks.
Image-to-Image Translation: Methods and Applications provides an overview of the image-to-image works developed in recent years. The authors draw attention to some of the key techniques developed in the field and discuss the effects of image-to-image translation on the research and industry community.
Methods
Dataset and Model Brief
In this project, we plan to use Tensorflow and base our experiment on both Kaggle notebook (with TPU V3-8 as an accelerator) and Google Colab (with GPU as an accelerator), which allow us to compare and evaluate the runtime performance of our project. We ran the smae code on both platforms mainly because Kaggle Notebooks requires user to queue for TPU (sometimes people need to queue for 1-2 hours to acess the TPU). Therefore, we wish to also ran our experiment on other platforms, and, in the meantime, see how our model perform without TPU.
Our dataset, provided by Kaggle, consists of four parts:
- monet_jpg - 300 Monet paintings sized 256x256 in JPEG format
- monet_tfrec - 300 Monet paintings sized 256x256 in TFRecord format
- photo_jpg - 7028 photos sized 256x256 in JPEG format
- photo_tfrec - 7028 photos sized 256x256 in TFRecord format
The monet_tfrec and monet_jpg directories contain the same painting images, and the photo_tfrec and photo_jpg directories contain the same photos. In our experiment, we load and process the data from monet_tfrec and photo_tfrec to create our dataset: we decode the tfrec file to jpeg file, resize all the files to three channel image of size [256, 256, 3], and zip all of them to a dataset.
It is important to note that the input training data are not pair images. That is, for each monet image provided, there is no corresponding photo image; and for each real photo image, there is no corresponding monet image. The differences between paired and unpaired image inputs are shown in the below image.
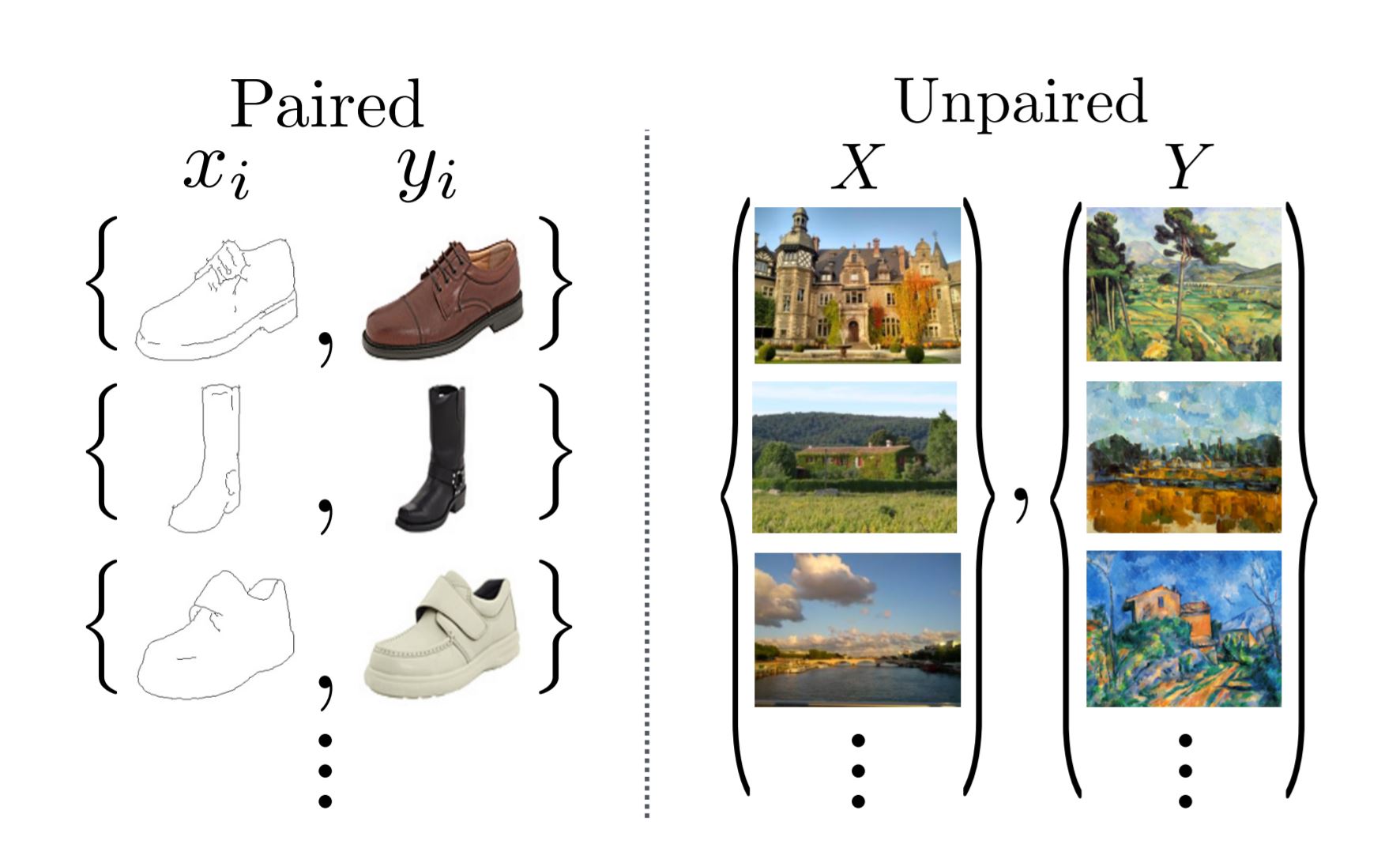 |
|---|
| Paired and unpaired image inputs from the original CycleGAN paper |
The unpaired nature of our training data promotes us to employ the Cycle-Consistent Adversarial Networks (CycleGAN). CycleGAN is a recently-developed approach “for learning to translate an image from a source domain X to a target domain Y in the absence of paired examples”. Traditional image-to-image translation solution based on Conditional Adversarial Networks depends on the availability of training examples where the same data is available in both domains. That is, say f: X->Y is a map from a source domain X to a target domain Y. Then, the training sample for Conditional Adversarial Networks based image-to-image translation model should looks like (x, f(x)) pair. However, CycleGAN eliminated the need for a paired image by making a two-step transformation of the source domain image - first by trying to map it to the target domain and then back to the original image. (More details of CycleGAN will be discussed in discussion section)
After the CycleGAN model is trained for 40 epochs, we use the trained model to make predictions: for each photo in the photo dataset, we take it as an input and output a Monet version of that photo.
Before reading the following sections, we recommend to read the Discussion section (More about CycleGAN) first :)
Loss Functions
In this model, we used four kinds of loss functions.
- For the generator_loss, we use the BinaryCrossentropy as their loss function. BinaryCrossentropy is a typical loss function that computes the cross-entropy loss between true labels and predicted labels. generator_loss is based on the results from corresponding discriminator.
- For the discriminator_loss, we first compute the loss of real inputs and then compute the loss of generated input, both using the BinaryCrossentropy. This discriminator loss is the average of the real and generated loss.
- We also defined the cycle consistency loss which measures if original photo and the twice transformed photo to be similar to one another. That is, for example, take a real_monet image, put it into a photo_generator to generate a fake_photo, and put this fake_photo into a monet_generator to produce a fake_monet. The cycle consistency loss meassures the difference between real_monet and fake_monet.
- Finally, we defined the identity loss which compares the image with its generator. That is, for example, take a real_monet image, put it into a monet_generator, and compare the real_monet with the generated fake_monet.
Optimizers
monet_generator_optimizer = optimizers.Adam(2e-4, beta_1=0.5)
photo_generator_optimizer = optimizers.Adam(2e-4, beta_1=0.5)
monet_discriminator_optimizer = optimizers.Adam(2e-4, beta_1=0.5)
photo_discriminator_optimizer = optimizers.Adam(2e-4, beta_1=0.5)
Generator and Discriminator Basics
- To build the Generators and Discriminators, we used the technique of Upsample and Downsample that is commonly used in implementation of Deep Convolutional GAN(DCGAN). Details of DCGAN can be seen in this research paper and this article, and our implementation of Upsample and Downsample can be found in our notebooks.
- The Downsample, as the name suggests, reduces the 2D dimensions, the width and height, of the image by the stride. It uses the Conv2D layer where the stride is the length of the step the filter takes; since we use the stride 2, the filter is applied to every other pixel, hence reducing the weight and height by 2.
- Upsample does the opposite of downsample and increases the dimensions of the of the image. It uses Conv2DTranspose which does basically the opposite of a Conv2D layer.
- Our generator first downsamples the input image and then upsample, and we concatenate the output of the downsample layer to the upsample layer in a symmetrical fashion.
- For the discriminator, however, we just need a simple downsampling.
-
For the activiation, we used the LeakyReLU, which has become a best practice when developing deep convolutional neural networks generally.
-
Moreover, instead of using batch normalization, we used the instance normalization.
Detailed information of monet_generator
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_2 (InputLayer) [(None, 256, 256, 3 0 []
)]
sequential (Sequential) (None, 128, 128, 64 3072 ['input_2[0][0]']
)
sequential_1 (Sequential) (None, 64, 64, 128) 131328 ['sequential[0][0]']
sequential_2 (Sequential) (None, 32, 32, 256) 524800 ['sequential_1[0][0]']
sequential_3 (Sequential) (None, 16, 16, 512) 2098176 ['sequential_2[0][0]']
sequential_4 (Sequential) (None, 8, 8, 512) 4195328 ['sequential_3[0][0]']
sequential_5 (Sequential) (None, 4, 4, 512) 4195328 ['sequential_4[0][0]']
sequential_6 (Sequential) (None, 2, 2, 512) 4195328 ['sequential_5[0][0]']
sequential_7 (Sequential) (None, 1, 1, 512) 4195328 ['sequential_6[0][0]']
sequential_8 (Sequential) (None, 2, 2, 512) 4195328 ['sequential_7[0][0]']
concatenate_2 (Concatenate) (None, 2, 2, 1024) 0 ['sequential_8[0][0]',
'sequential_6[0][0]']
sequential_9 (Sequential) (None, 4, 4, 512) 8389632 ['concatenate_2[0][0]']
concatenate_3 (Concatenate) (None, 4, 4, 1024) 0 ['sequential_9[0][0]',
'sequential_5[0][0]']
sequential_10 (Sequential) (None, 8, 8, 512) 8389632 ['concatenate_3[0][0]']
concatenate_4 (Concatenate) (None, 8, 8, 1024) 0 ['sequential_10[0][0]',
'sequential_4[0][0]']
sequential_11 (Sequential) (None, 16, 16, 512) 8389632 ['concatenate_4[0][0]']
concatenate_5 (Concatenate) (None, 16, 16, 1024 0 ['sequential_11[0][0]',
) 'sequential_3[0][0]']
sequential_12 (Sequential) (None, 32, 32, 256) 4194816 ['concatenate_5[0][0]']
concatenate_6 (Concatenate) (None, 32, 32, 512) 0 ['sequential_12[0][0]',
'sequential_2[0][0]']
sequential_13 (Sequential) (None, 64, 64, 128) 1048832 ['concatenate_6[0][0]']
concatenate_7 (Concatenate) (None, 64, 64, 256) 0 ['sequential_13[0][0]',
'sequential_1[0][0]']
sequential_14 (Sequential) (None, 128, 128, 64 262272 ['concatenate_7[0][0]']
)
concatenate_8 (Concatenate) (None, 128, 128, 12 0 ['sequential_14[0][0]',
8) 'sequential[0][0]']
conv2d_transpose_7 (Conv2DTran (None, 256, 256, 3) 6147 ['concatenate_8[0][0]']
spose)
==================================================================================================
Total params: 54,414,979
Trainable params: 54,414,979
Non-trainable params: 0
Detailed information of monet_discriminator
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_image (InputLayer) [(None, 256, 256, 3)] 0
sequential_30 (Sequential) (None, 128, 128, 64) 3072
sequential_31 (Sequential) (None, 64, 64, 128) 131328
sequential_32 (Sequential) (None, 32, 32, 256) 524800
zero_padding2d (ZeroPadding (None, 34, 34, 256) 0
2D)
conv2d_113 (Conv2D) (None, 31, 31, 512) 2097152
instance_normalization_30 ( (None, 31, 31, 512) 1024
InstanceNormalization)
leaky_re_lu_19 (LeakyReLU) (None, 31, 31, 512) 0
zero_padding2d_1 (ZeroPaddi (None, 33, 33, 512) 0
ng2D)
conv2d_114 (Conv2D) (None, 30, 30, 1) 8193
=================================================================
Total params: 2,765,569
Trainable params: 2,765,569
Non-trainable params: 0
Detailed information of photo_generator
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 256, 256, 3 0 []
)]
sequential_15 (Sequential) (None, 128, 128, 64 3072 ['input_3[0][0]']
)
sequential_16 (Sequential) (None, 64, 64, 128) 131328 ['sequential_15[0][0]']
sequential_17 (Sequential) (None, 32, 32, 256) 524800 ['sequential_16[0][0]']
sequential_18 (Sequential) (None, 16, 16, 512) 2098176 ['sequential_17[0][0]']
sequential_19 (Sequential) (None, 8, 8, 512) 4195328 ['sequential_18[0][0]']
sequential_20 (Sequential) (None, 4, 4, 512) 4195328 ['sequential_19[0][0]']
sequential_21 (Sequential) (None, 2, 2, 512) 4195328 ['sequential_20[0][0]']
sequential_22 (Sequential) (None, 1, 1, 512) 4195328 ['sequential_21[0][0]']
sequential_23 (Sequential) (None, 2, 2, 512) 4195328 ['sequential_22[0][0]']
concatenate_9 (Concatenate) (None, 2, 2, 1024) 0 ['sequential_23[0][0]',
'sequential_21[0][0]']
sequential_24 (Sequential) (None, 4, 4, 512) 8389632 ['concatenate_9[0][0]']
concatenate_10 (Concatenate) (None, 4, 4, 1024) 0 ['sequential_24[0][0]',
'sequential_20[0][0]']
sequential_25 (Sequential) (None, 8, 8, 512) 8389632 ['concatenate_10[0][0]']
concatenate_11 (Concatenate) (None, 8, 8, 1024) 0 ['sequential_25[0][0]',
'sequential_19[0][0]']
sequential_26 (Sequential) (None, 16, 16, 512) 8389632 ['concatenate_11[0][0]']
concatenate_12 (Concatenate) (None, 16, 16, 1024 0 ['sequential_26[0][0]',
) 'sequential_18[0][0]']
sequential_27 (Sequential) (None, 32, 32, 256) 4194816 ['concatenate_12[0][0]']
concatenate_13 (Concatenate) (None, 32, 32, 512) 0 ['sequential_27[0][0]',
'sequential_17[0][0]']
sequential_28 (Sequential) (None, 64, 64, 128) 1048832 ['concatenate_13[0][0]']
concatenate_14 (Concatenate) (None, 64, 64, 256) 0 ['sequential_28[0][0]',
'sequential_16[0][0]']
sequential_29 (Sequential) (None, 128, 128, 64 262272 ['concatenate_14[0][0]']
)
concatenate_15 (Concatenate) (None, 128, 128, 12 0 ['sequential_29[0][0]',
8) 'sequential_15[0][0]']
conv2d_transpose_15 (Conv2DTra (None, 256, 256, 3) 6147 ['concatenate_15[0][0]']
nspose)
==================================================================================================
Total params: 54,414,979
Trainable params: 54,414,979
Non-trainable params: 0
Detailed information of photo_discriminator
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_image (InputLayer) [(None, 256, 256, 3)] 0
sequential_33 (Sequential) (None, 128, 128, 64) 3072
sequential_34 (Sequential) (None, 64, 64, 128) 131328
sequential_35 (Sequential) (None, 32, 32, 256) 524800
zero_padding2d_2 (ZeroPaddi (None, 34, 34, 256) 0
ng2D)
conv2d_118 (Conv2D) (None, 31, 31, 512) 2097152
instance_normalization_33 ( (None, 31, 31, 512) 1024
InstanceNormalization)
leaky_re_lu_23 (LeakyReLU) (None, 31, 31, 512) 0
zero_padding2d_3 (ZeroPaddi (None, 33, 33, 512) 0
ng2D)
conv2d_119 (Conv2D) (None, 30, 30, 1) 8193
=================================================================
Total params: 2,765,569
Trainable params: 2,765,569
Non-trainable params: 0
Discussion
In this project, we grabbed the dataset from Kaggle and coded everything from scratch, including loading the data, configuring the optimizers, creating the convolutional generators and discriminators, building the CycleGAN model, and finally training the model. All of our work can be seen in Kaggle notebook and Google Colab notebook. Though we did experiment on different parameters, our main purpose is not investigating the optimal parameters for our model. Instead, we focus more on learning the idea of CycleGAN, understanding its relationship with tranditional GANs, build a CycleGAN by ourselves, and display it through Gradio application. In fact, compared to the well-crafted CycleGAN model presented in the original CycleGAN paper, our model is very unrefined and poorly-trained. However, building the model from nothing is challenging enough, and we did try to improve it in different ways.
More about CycleGAN
First, we will provide more details of our CycleGAN model for audience to understand. The GAN model architecture involves two sub-models: a generator model for generating new examples and a discriminator model for classifying whether generated examples are real (from the domain) or fake(generated by the generator model).
- The generator model g: R^n -> X takes a fixed-length random vector as input and generates a sample in the domain. The vector is drawn randomly according to a Gaussian distribution, and we use it as a seed for our generative process.
- The discriminator model d: X -> {0,1} takes an example from the domain as input (real or generated) and predicts alabel of real or fake (generated).
The generator and discriminator will be trained together. Generator will generate a batch of samples, feeding into the discriminator along with real samples. The discriminator will be updated to better discriminate between fake and real samples, while the generator will then be updated based on how well it fools the discriminator.
The CycleGAN is an extension of the GAN architecture that involves the simultaneous training of two generator models and two discriminator models. We can summarize it as:
- Generator Model 1:
- Input: Takes input form collection 1.
- Output: Generates a sample in collection 2.
- Discriminator Model 1:
- Input: Takes real samples from collection 1 and output from Generator Model 2.
- Output: Likelihood of a sample is from collection 1.
- Generator Model 2:
- Input: Takes input form collection 2.
- Output: Generates a sample in collection 1.
- Discriminator Model 2:
- Input: Takes real samples from collection 2 and output from Generator Model 1.
- Output: Likelihood of a sample is from collection 2.
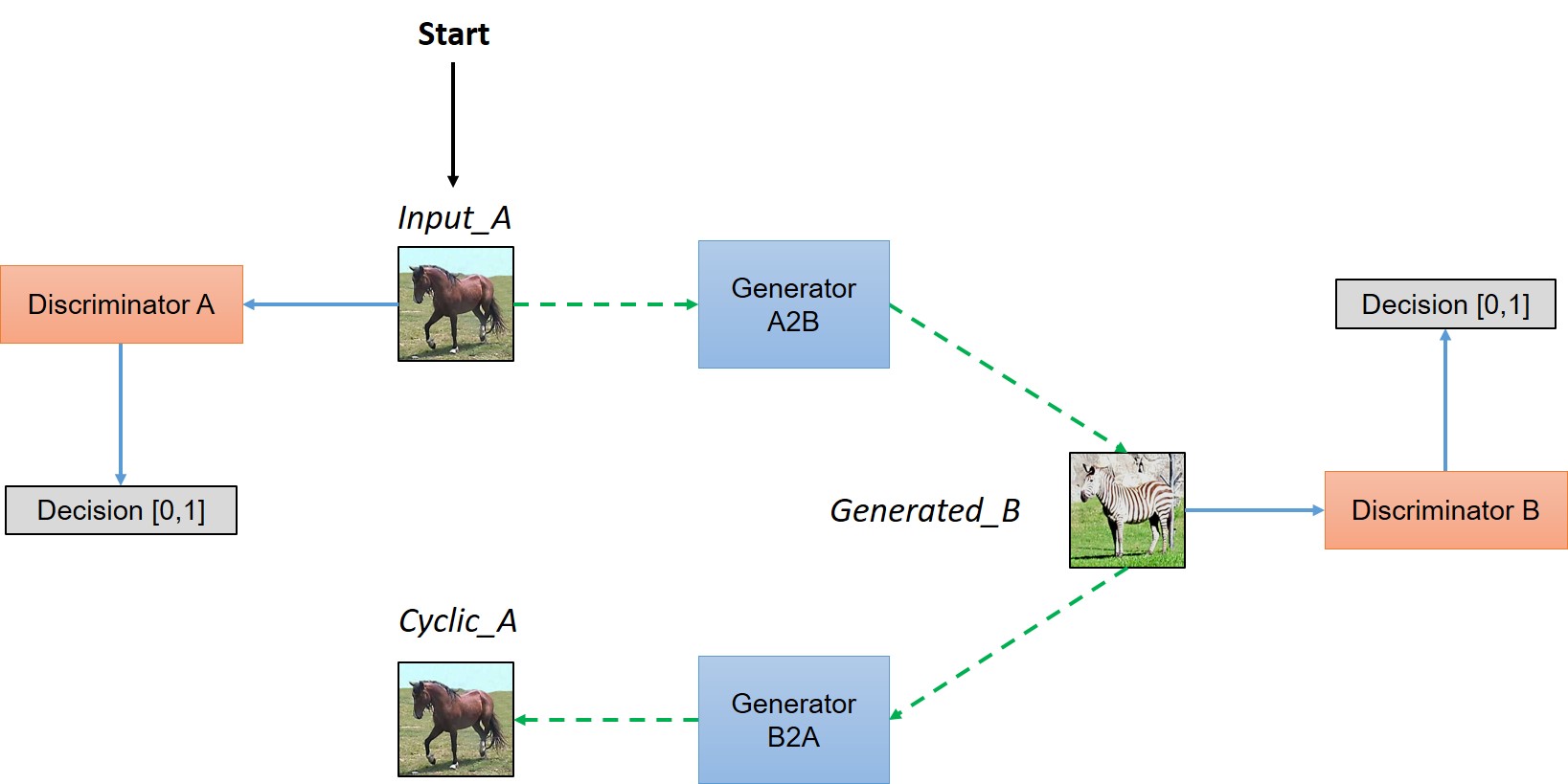 |
|---|
|
| Simplified view of CycleGAN Architecture from Understanding and Implementing CycleGAN in TensorFlow |
The above image is a simple illustration of a CycleGAN architecture where collection 1 is the collection of horses images and collection 2 is the collection of zebra images. Moreover,
- Generator Model 1 (Generator A2B):
- Input: Take real horse images.
- Output: Generate fake zebra images.
- Discriminator Model 1 (Discriminator B):
- Input: Takes real zebra images and fake zebra images generated by Generator Model 1.
- Output: Likelihood of a sample is a real zebra image.
- Generator Model 2 (Generator B2A):
- Input: Take real zebra images.
- Output: Generate fake horse images.
- Discriminator Model 2 (Discriminator A):
- Input: Takes real horse images and fake horse images generated by Generator Model 2.
- Output: Likelihood of a sample is a real horse image.
In our case, collection 1 is the collection of real photos and collection 2 is the collection of Monet images. We call the Generator Model 1 the monet_generator, the Generator Model 2 the photo_generator, the Discriminator Model 1 the photo_discriminator, and the Discriminator Model 2 the monet_discriminator.
Main Experimental Results
Then, we will reveal some of our predictions from the trained monet_generator:
 |
 |
|---|---|
| Images on the left reveal predictions from the model trained in Google Colab | Images on the right reveal predictions from the model trained in Kaggle Notebook |
The losses are not as interesting as the output, but here is what we have for training the model for 40 epoches:
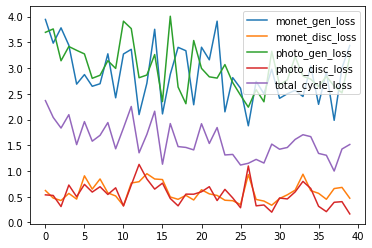 |
|---|
| Losses of the CycleGAN model trained in Google Colab |
We can see that the losses are not converging as well as other models we used to see, especially the generator losses and discriminator losses. This makes sense as GANs are notoriously hard to converge as the Discriminator and Generator in a GAN training scheme work one against the other. That is, as the generator gets better with next epochs, the discriminator performs worse because the discriminator can’t easily tell the difference between a real and a fake one. Therefore, though the losses are not converging very well, it doesn’t mean that our model didn’t learn anything. Instead, from our generated images, we can say our model did learn a lot about how to accomplish its job.
Dealing with image arguments
*Since the model perform similarly on both platforms, we only ran this experiment on Google Colab
We can see that for some input photos, our model effectively generates a Monet style version of the input. However, it is also notable that some output still contains a lot of features that do not fit Monet style. Observing the inputs and their corresponding outputs, we realized that the effectiveness of the model is largely affected by the traits of the original input photo, including image brightness, saturation, contrast. Therefore, if we could manually process these arguments (for example, add more variability during the training process to avoid extreme cases), we expect to see better results. In fact, we have written some scripts for processing these arguments. Unfortunately, due to time limitations, we may not be able to finish the experiment, but it would definitely be a good topic to explore for future work.
with strategy.scope():
def DiffAugment(x, policy='', channels_first=False):
if policy:
if channels_first:
x = tf.transpose(x, [0, 2, 3, 1])
for p in policy.split(','):
for f in AUGMENT_FNS[p]:
x = f(x)
if channels_first:
x = tf.transpose(x, [0, 3, 1, 2])
return x
def rand_brightness(x):
magnitude = tf.random.uniform([tf.shape(x)[0], 1, 1, 1]) - 0.5
x = x + magnitude
return x
def rand_saturation(x):
magnitude = tf.random.uniform([tf.shape(x)[0], 1, 1, 1]) * 2
x_mean = tf.reduce_sum(x, axis=3, keepdims=True) * 0.3333333333333333333
x = (x - x_mean) * magnitude + x_mean
return x
def rand_contrast(x):
magnitude = tf.random.uniform([tf.shape(x)[0], 1, 1, 1]) + 0.5
x_mean = tf.reduce_sum(x, axis=[1, 2, 3], keepdims=True) * 5.086e-6
x = (x - x_mean) * magnitude + x_mean
return x
AUGMENT_FNS = {
'color': [rand_brightness, rand_saturation, rand_contrast],
}
def aug_fn(image):
return DiffAugment(image,"color")
Ethics
Is this project ethical?
We see this project as generally ethical as long as the model is used with good and honest intentions. While the model could be used to generate counterfeit art, the model also offers positive opportunities for learning about art styles and different kinds of neural networks and how AI and art can be interconnected. We are aware of the risks of a model that could be used nefariously but believe that the level at which we seek to apply it has more value for educational purposes and will not reach an audience with malicious intent.
What parts of the project have historically faced ethical concerns?
When art is generated by or through technology, there tends to be the question of did the technology itself create the art? While it could be attributed to the person who built the technology, more often than not is the technology based on another person’s art style. In fact, technology allows artist to create art in new ways, as stated in the article Computers Do Not Make Art, People Do where the author mentions how in their research that, “seeing an artist create something wonderful with new technology is thrilling, because each piece is a step the evolution of new forms of art” (Hertzmann). On the other hand, there exists ethical concerns over the ownership of the art and whether one’s images can be used in the model (either as an input source or a style basis), but this can be best resolved by only using images where permission has been granted.
How diverse is our team?
Our project team is diverse and comes from different backgrounds and identities. We all have varying levels of experience and background with numerous forms of art and modelling. We hope to apply our knowledge to the best of our abilities in this project and will use our different experiences to make a well rounded model with the least amount of bias possible.
Is our data valid for its intended use? Could there be bias in our dataset?
Our data is valid and would not contain bias as we are using a collection of many different images. Although some of the images could be more easily turned into art than others, our model does not predict things such as statistics or outcomes but rather transforms images. Consequently, we see less of an ethical concern with bias in the data and more on the side of the outcome of the model.
How might we negatively affect individuals’ with the model?
While we are using the image style of a certain artist, we are not attempting to take credit for or plagiarise their work. Moreover, we recognize how the original art should be attributed to the artist of the original image and how the original images we input into the model to be converted still belong to the original owner. There exists the question of who the converted art belongs to as it exists in a grey area between the artist style, the original image owner, and the user of the model.
Reflection
In this project, we’ve studied how to accomplish complicated image-to-image translation jobs through the newly-developed CycleGAN architecture. However, our way of implementing the CycleGAN model is not polished, and there are a lot of approaches to improve the performance of our model. These could be interesting topics for continuing works.
-
In our experiment, we only built a basic CycleGAN model with rudimentary generators and discriminators. They did work, but we didn’t spend enough time on improving their performance. In fact, if we have more time, we can definitely test more on the parameters and neural network layers. Moreover, in real-life projects and scientific research, there are a huge amount of known and emerging approaches to improve the performance of GANs. For example, one can do feature matching, minibatch discrimination, one-sided label smoothing, or historical averaging. Some of these techniques may also be applied to improving the behavior of our CycleGAN model, and investigating which of them work well can be an interesting research topic.
-
Besides the CycleGAN model itself, we can also improve our results by looking into this specific question. For example, we mentioned in our discussion section that the effectiveness of the model is largely affected by the traits of the original input photo, including image brightness, saturation, contrast. Thus, if we could study more on computer vision and learn more about how to deal with these image arguments, we would be able to better conquer the problem caused by extreme image augments.
-
Next time, we would start coding earlier, so that we could have more time exploring and improving the final results. Ideally, we also would have been able to try to run our model on the server. Unfortunately, the server ran out of disk space, but had we had the chance to use the server, we would have liked to run our model for more epochs, and see if the losses decrease any further.
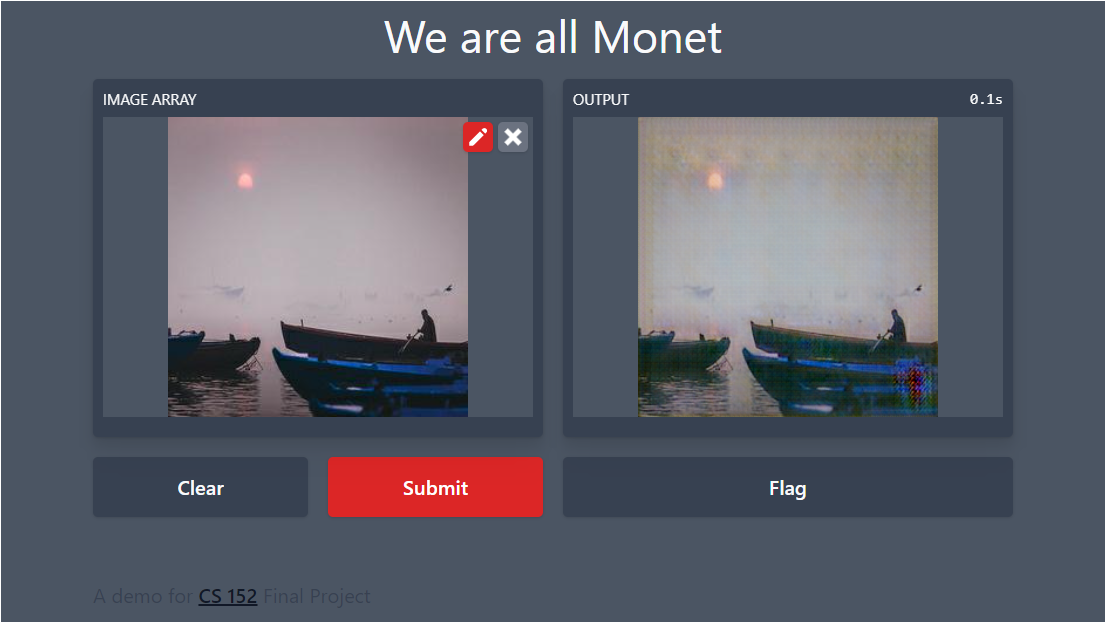
Gradio Application
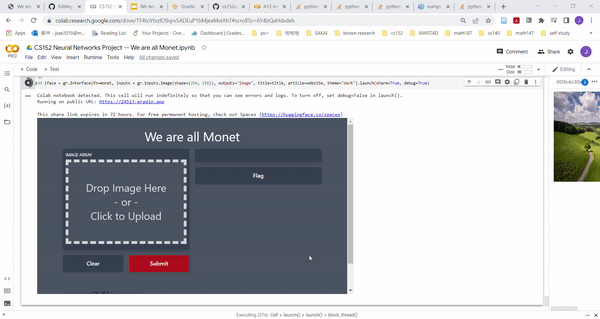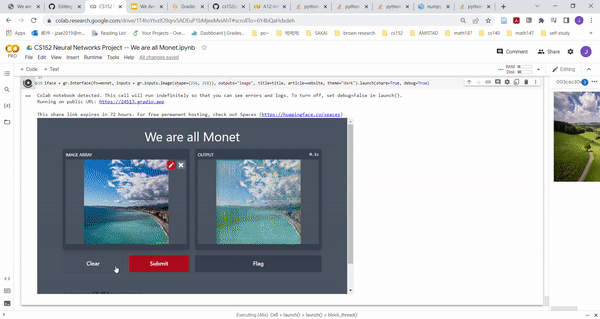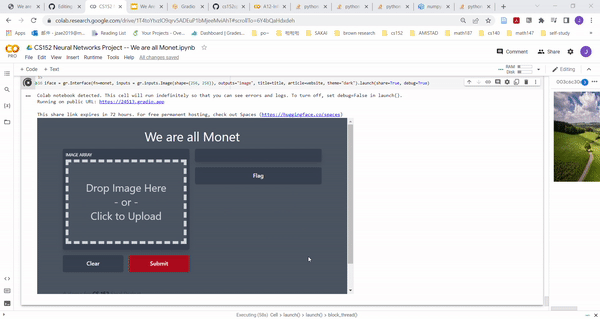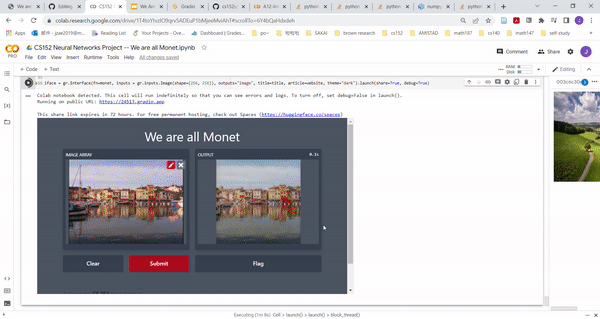 |
|---|
 |
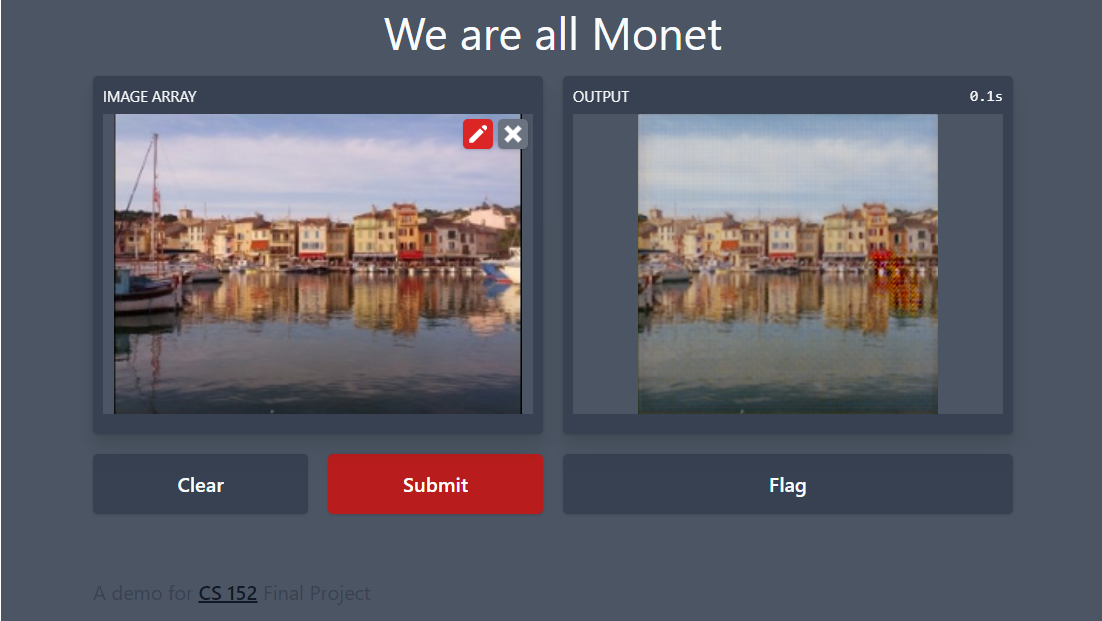 |
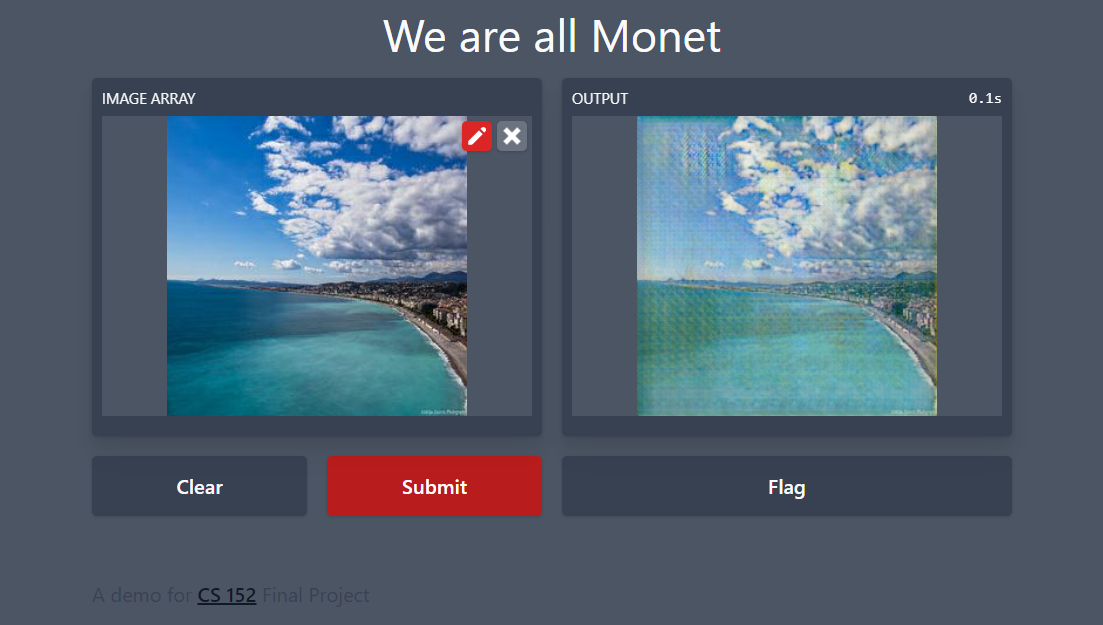 |
| Gradio Demo of our model |
Citations
- Goodfellow, Ian J., et al. “Generative Adversarial Nets.” 10 June 2014.
- Isola, Phillip, et al. “Image-to-Image Translation with Conditional Adversarial Networks.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 26 Nov. 2018.
- Pang, Yingxue, et al. “Image-to-Image Translation: Methods and Applications.” IEEE Transactions on Multimedia, 3 July 2021.
- Zhu, Jun-Yan, et al. “Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks.” 2017 IEEE International Conference on Computer Vision (ICCV), 24 Aug. 2020.
- Radford, Alec et al. “Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks.” CoRR abs/1511.06434 (2016): n. pag.